
Sonstige Berichte
Sammlungsverwaltung mit der kostenlosen Fossilien-Datenbank PalCol


- Details
- Kategorie: Vermischtes
- Veröffentlicht: Freitag, 17. Dezember 2021 12:23
- Geschrieben von Hannes Löser
- Zugriffe: 4631
Datenbanken dienen dazu, große Informationsmengen zu erfassen, sie zu verarbeiten, nach ihnen zu suchen, und sie nach bestimmten Mustern auszugeben. Sie werden immer dort angewendet, wo Textdateien oder Kalkulationstabellen nicht mehr zur Datenspeicherung ausreichen, also eine spezielle Suche, Ausgabe oder Modifikation der Daten schwer zu realisieren ist. In naturwissenschaftlichen Museen und großen Sammlungen dienen Datenbanken prinzipiell dazu, Auskunft geben zu können, was überhaupt vorhanden ist. Eine konkrete Anfrage nach einem bestimmten Stück (z. B. einem Typusexemplar) oder zu Material eines bestimmten Fundortes kann so schnell beantwortet werden.
Für die Sammlung des Hobby-Paläontologen gilt das nicht unbedingt. Zum einen ist sie meist überschaubar und zum anderen, muss viel seltener Auskunft erteilt werden. Und in letzerem Fall geht es meist schneller, den entsprechenden Schub aufzuziehen und zu schauen, was für Material man zum Beispiel von einem bestimmten Fundpunkt besitzt. Die Freude am Sammeln, an der Präparation und letztendlich an der Ästhetik der Stücke steht bei vielen Sammlern im Vordergrund. Es gibt jedoch auch Sammler, die sich Jahrzehnte lang mit einem Aufschlussgebiet oder einer Fossilgruppe intensiv beschäftigen und neben dem Material auch viel Wissen zusammentragen. Erreicht eine Sammlung mehrere Tausend Posten und damit das Niveau einer Forschungssammlung, ist es sinnvoll, über die Anwendung einer Datenbank nachzudenken. Mit deren Hilfe kann man nicht nur ermitteln, was sich in der Sammlung befindet, sondern zum Beispiel auch, wo eine bestimmte Art oder Gattung vorkommt, oder welche Arten von einem bestimmten Fundort vorliegen. Es lässt sich nachvollziehen, wann und wo Material gefunden wurde, Bestimmungen können mit Literatur verknüpft werden und natürlich können auch Bilder zum Bestandteil der Datenbasis gemacht werden
Im Folgenden soll kurz die Anwendung PalCol vorgestellt werden. PalCol ist eine Anwendungsbibliothek des Datenbanksystems Hdb2Win, das ursprünglich entwickelt wurde, um paläontologische Daten in einer Forschungsdatenbank zu verwalten. Im Vergleich zu einer Tabellenkalkulation, wo meist nur mit einer Tabelle gearbeitet wird, besteht eine Datenbank aus einer Vielzahl von Tabellen. Eine jede speichert bestimmte Daten wie – im Fall von PalCol – Lokalitäten, Regionen, Familien, Gattungen, Arten usw. Auf diese Weise wird eine Lokalität nur einmal gespeichert, wie auch jede Region, Familie usw. in ihrer jeweiligen Tabelle. Zwischen den Tabellen bestehen Beziehungen. So wird eine Lokalität auf eine Region verweisen, eine Gattung auf eine Familie usw. Diese Methode hat zwei Vorteile. Erstens wird jede Art von Datenbankeintrag nur einmal erfasst. Ist eine Art, Gattung, Familie, oder was auch immer, einmal erfasst, kann im folgenden auf diesen Datensatz zurückgegriffen oder darauf verwiesen werden. Zweitens sind Änderungen leichter nachzuführen. Hat man sich zum Beispiel in der Schreibweise einer Lokalität geirrt, wird der korrekte Name lediglich in der Tabelle der Lokalitäten korrigiert und wirkt sich so über die Verknüpfungen anderer Tabellen zur Tabelle der Lokalitäten aus. Das betrifft ebenso die Zuordnung einer Art zu einer Gattung oder einer Gattung zu einer Familie. Wer sich mit der Taxonomie seiner Funde beschäftigt, weiß, dass sich diese Daten ändern.
Ein Beispiel: Als die gemeine Taubenauster Exogyra columba vor ein paar Jahrzehnten plötzlich zum Wortungetüm Rhynchostreon suborbiculatum mutierte, musste in der Datenbank nur ein einziger Datensatz geändert werden. Wer seine Daten in einer Textdatei oder in einer Tabellenkalkulation speichert, muss jede Änderung manuell nachführen, was nicht nur aufwändig ist, sondern auch Fehler geradezu provoziert.
Eine Anwendungsbibliothek (so wie PalCol) besteht aus den Tabellen, Konfigurationsdateien, Erfassungsmasken und einigen kleinen Programmen. Die Datenstruktur ist nicht Teil des Datenbank-Programms und sie ist nicht begrenzt. Das bedeutet, dass der Anwender eigene Tabellen und eigene Datenfelder hinzufügen kann. Das Datenformat (dBase III) ist veröffentlichtlicht und einzelne Tabellen können mit anderen Programmen geöffnet werden. Dabei geht allerdings der logische Zusammenhang zwischen den Tabellen verloren, da die Verknüpfung der Tabellen von den Konfigurationsdateien der Anwendungsbibliothek bestimmt werden. PalCol ist nur eine unter mehreren für das Datenbanksystem Hdb2Win entwickelten Anwendungsbibliotheken. Wir werden hier jedoch nur über PalCol sprechen.

Nach dem Öffnen einer PalCol Datenbasis (Abb. 1) wird eine Grafik mit wichtigen Tabellen und ihren Beziehungen untereinander gezeigt. Die Pfeile bedeuten in etwa "verwendet" oder "verweist auf". Durch das Anklicken eines Kästchens wird eine Tabelle zur aktuellen Tabelle erklärt und das Anklicken eines Knopfes innerhalb des Rahmens (Recherche, Sortierung, Anhängen) bezieht sich auf die ausgewählte Tabelle. Bei einer neu angelegten Datenbasis sind alle Auswahlknöpfe außer "Anhängen" gesperrt. Normalerweise erfolgt der Einstieg immer über die Datenbank der Sammlungsstücke, aber ebenso gut kann man in allen anderen Tabellen suchen, Daten erfassen oder verändern. Die Knöpfe außerhalb des Rahmens (Globale Suche, Kataloge etc., Reorganisation) stehen in keiner Beziehung zur gerade ausgewählten Datenbank, sondern beziehen sich auf die gesamte Datenbasis.
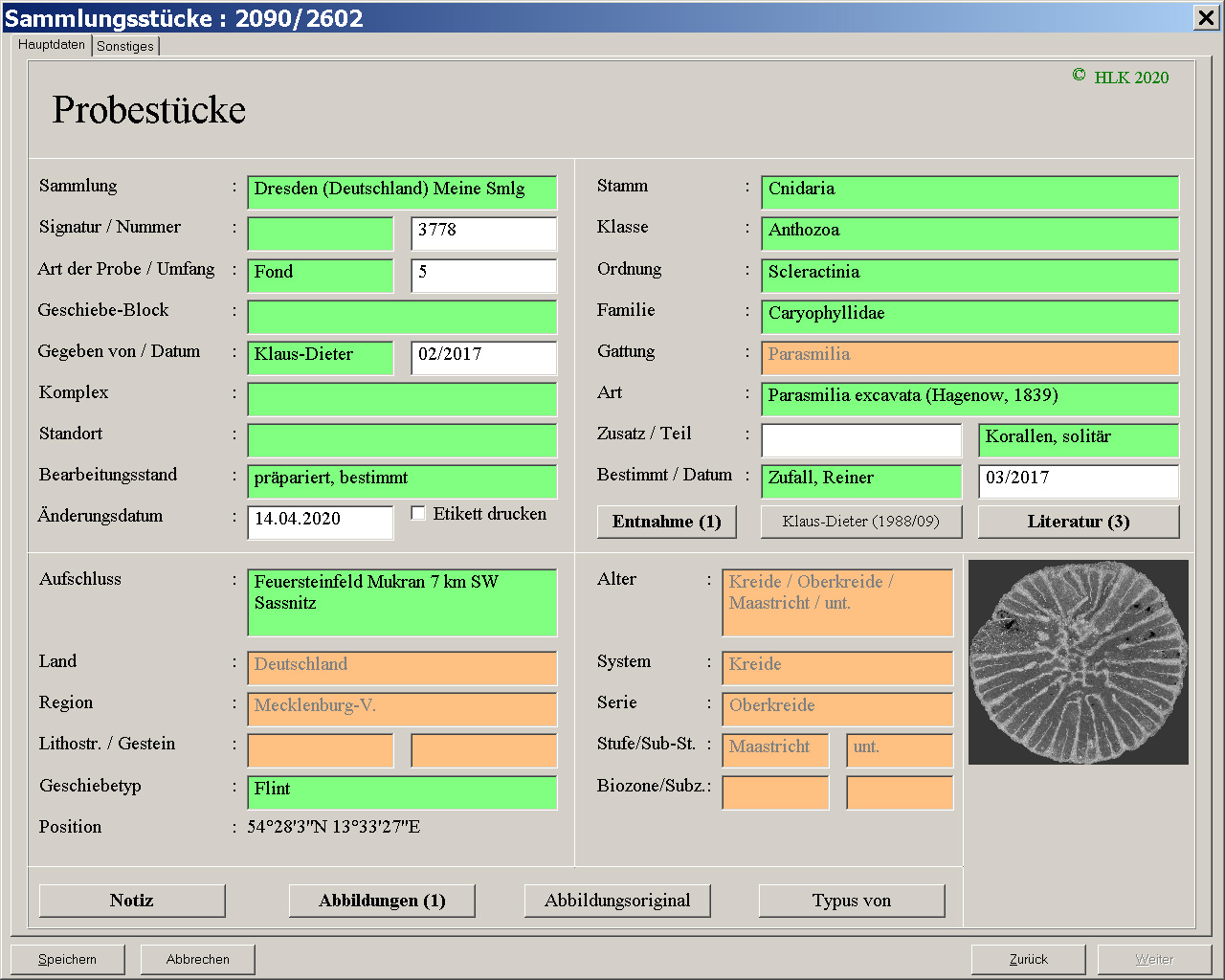
Abb. 2: Ansicht auf 1280 x 1024 Pixel vergrößern.
Abb. 2 zeigt exemplarisch die Erfassungsmaske der Tabelle der Sammlungsstücke. Die Tabelle enthält ziemlich viele Informationen. Wie man sieht, gibt es vier Gruppen von Felder: allgemeine Angaben, der Fundort, die Taxonomie und das Alter. Es sei gleich gesagt, dass überhaupt kein Zwang besteht, alle Felder auszufüllen. Das ist ganz dem Anwender überlassen und die Dokumentation (mehr dazu unten) gibt dazu ausreichend Hilfestellung. Allerdings, nach Daten, die nicht erfasst werden, kann auch nicht gesucht werden. Wie man auch sieht, kann eine Erfassungsmaske mehrere Seiten haben. Auch gibt es verschiedene Typen von Datenfeldern: in weiße Felder wird etwas eingetragen, grüne Felder verweisen auf Einträge anderer Tabellen und orangene Felder dienen ausschließlich der Suche und sind sonst gesperrt.
Für Anwender, denen die Erfassungsmaske zu überladen ist und nicht ausreichend Platz für ein Bild lässt, existiert eine vereinfachte Form, die im Programm geladen werden kann. Details dazu finden sich in der Dokumentation.
Die grün markierten Felder stellen – wie gesagt – eine Verbindung zu dem Eintrag einer anderen Tabelle dar. Soll beispielsweise in der Tabelle der Sammlungsstücke ein neuer Datensatz angehängt werden und man möchte zuerst den Fundort erfassen, klickt man in das Feld der Lokalität und drückt Enter oder gibt einen Buchstaben ein. Man erhält die Meldung, dass keine Datensätze vorhanden sind und man wird gefragt, ob man einen neuen Datensatz (in der Tabelle der Lokalitäten) anhängen möchte. Dies geht natürlich auch einher mit der Erfassung eines neuen Landes, einer Region und der Stratigraphie der Lokalität. Hat man nun schon Stücke (und Fundorte) erfasst, und man geht beim Anhängen eines neuen Stückes zum Feld der Lokalität und drückt Enter, öffnet sich an der rechten Seite eine Tabelle der vorhandenen Lokalitäten (Abb. 3). Wird ein Eintrag ausgewählt, werden vom Programm eine Reihe von Angaben ergänzt, nach denen gesucht werden kann (Abb. 4). Diese Angaben stammen aus dem entsprechenden Datensatz der Tabelle der Lokalitäten. Führt man nun im Feld der Lokalität einen Doppelklick aus oder drückt in Einfg-Taste, gelangt man in den ausgewähten Datensatz der Tabelle der Lokalitäten (Abb. 5). Bei einem Doppelklick in ein orangenes Feld gelangt man auch zu dem dahinter liegenden Datensatz der entsprechenden Tabelle. Bei einer Suche können dort Daten ausgewählt werden, aber verändert werden kann das Feld nicht.
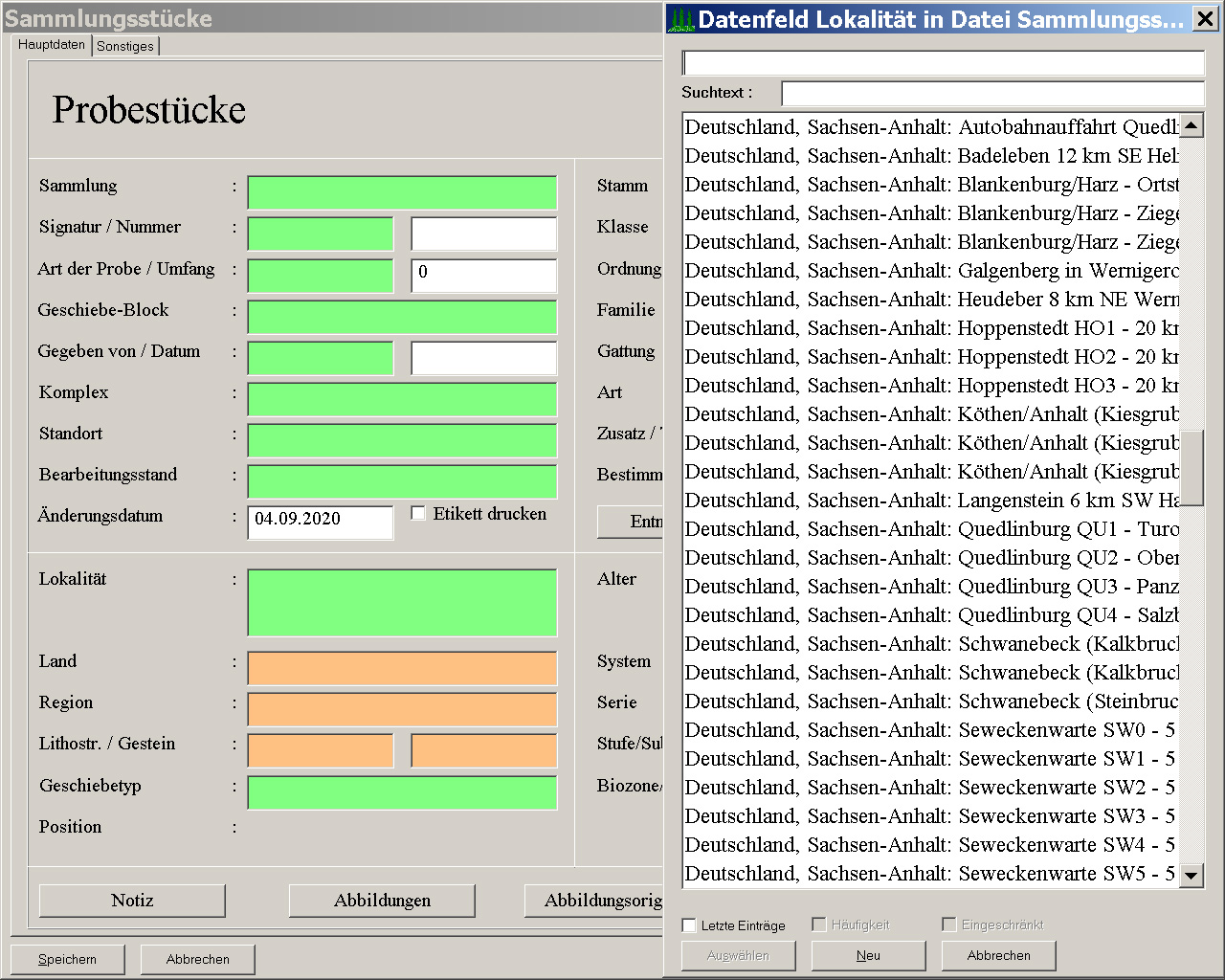
Abb. 3: Ansicht auf 1280 x 1024 Pixel vergrößern.
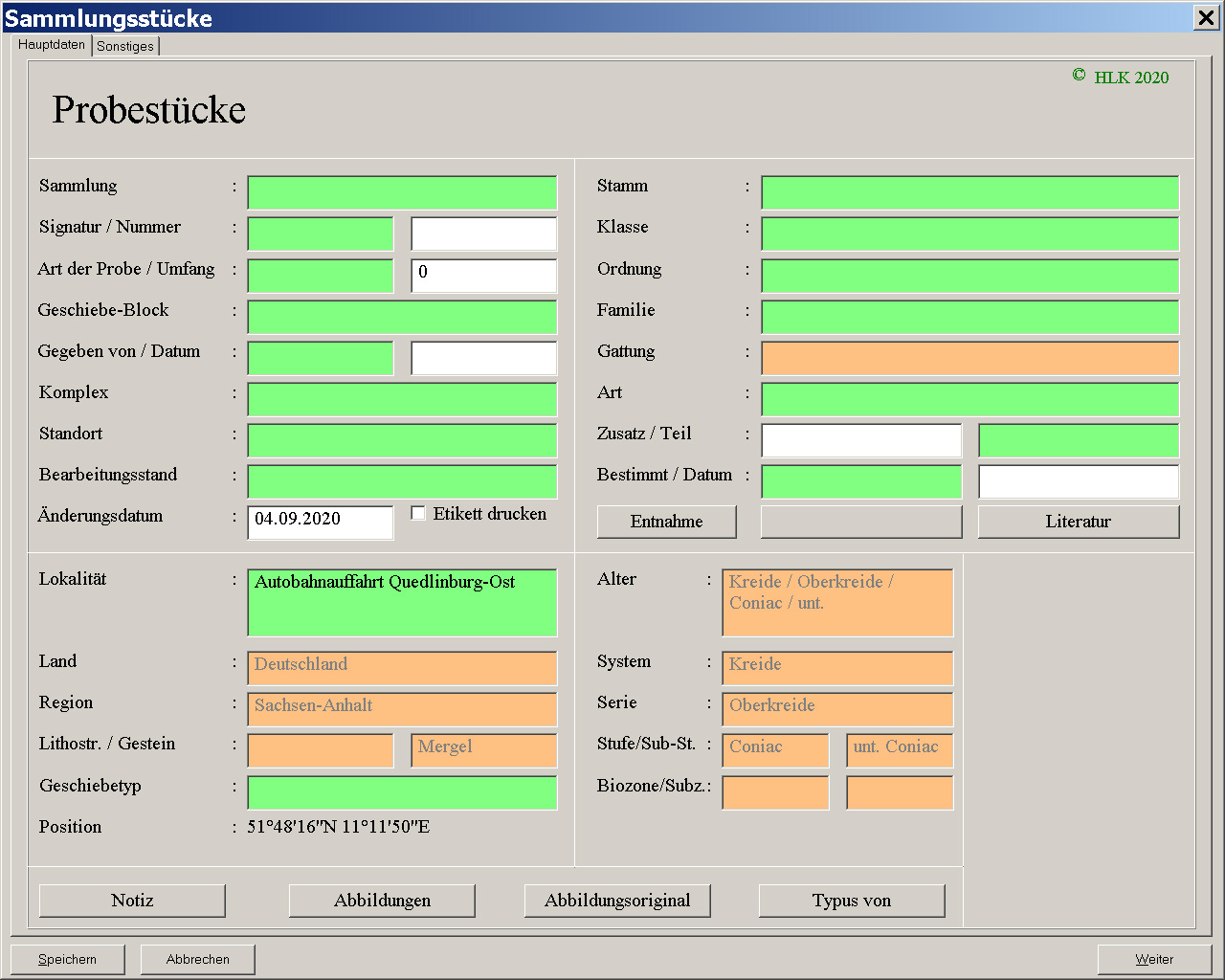
Abb. 4: Ansicht auf 1280 x 1024 Pixel vergrößern.

Abb. 5: Ansicht auf 1280 x 1024 Pixel vergrößern.
Im Block der Taxonomie wird seitens des Programms darauf geachtet, dass innerhalb der Datenbasis die Daten konsistent sind. Das bedeutet, dass eine Art immer zur selben Gattung, die Gattung immer zur selben Familie gestellt wird. Hängt man beispielsweise in einer mit Daten bestückten Datenbasis einen neuen Datensatz an, geht zum Feld der Art und wählt dort eine Art aus (Abb. 6), werden automatisch alle darüber liegenden Felder ergänzt (Abb. 7). Dieses Verfahren ist sinnvoll, wenn man weiß, dass eine Art bereits erfasst ist. Übrigens funktioniert das auch in anderen Ebenen: wird eine Familie ausgewählt, ergänzt das Programm alle darüber liegenden taxonomischen Ebenen.
Im umgedrehten Fall, wenn man also nicht sicher ist, welche Ebenen erfasst sind, beginnt man oben mit der Eingabe. Das heißt, man wählt den Stamm aus, geht dann zur Klasse, wo – wenn man Enter drückt – nur die Klassen des ausgewählten Stammes angezeigt werden (Abb. 8). So bewegt man sich weiter nach unten, bis man zur Art gelangt (die Gattung kann nicht ausgewählt werden) und nun alle Arten der entsprechenden Familie angezeigt bekommt (Abb. 9). Angenommen, die gesuchte Art findet sich nicht in der Liste und soll nun neu angehängt werden, klickt man auf Neu und ein neuer Eintrag in der Tabelle der Arten wird erfasst. Muss auch eine neue Gattung erfasst werden, setzt das Programm automatisch die Familie ein (Abb. 10). Diesen Eintrag sollte man nicht löschen, denn er ermöglicht erst die oben beschriebene Funktion. Sollte sich die Position z. B. einer Gattung ändern, wird diese Veränderung nur in dem entsprechenden Datensatz der Gattung durchgeführt und ein Konsistenz erhaltendes Programm gestartet. So werden alle betroffenen Datensätze korrigiert.
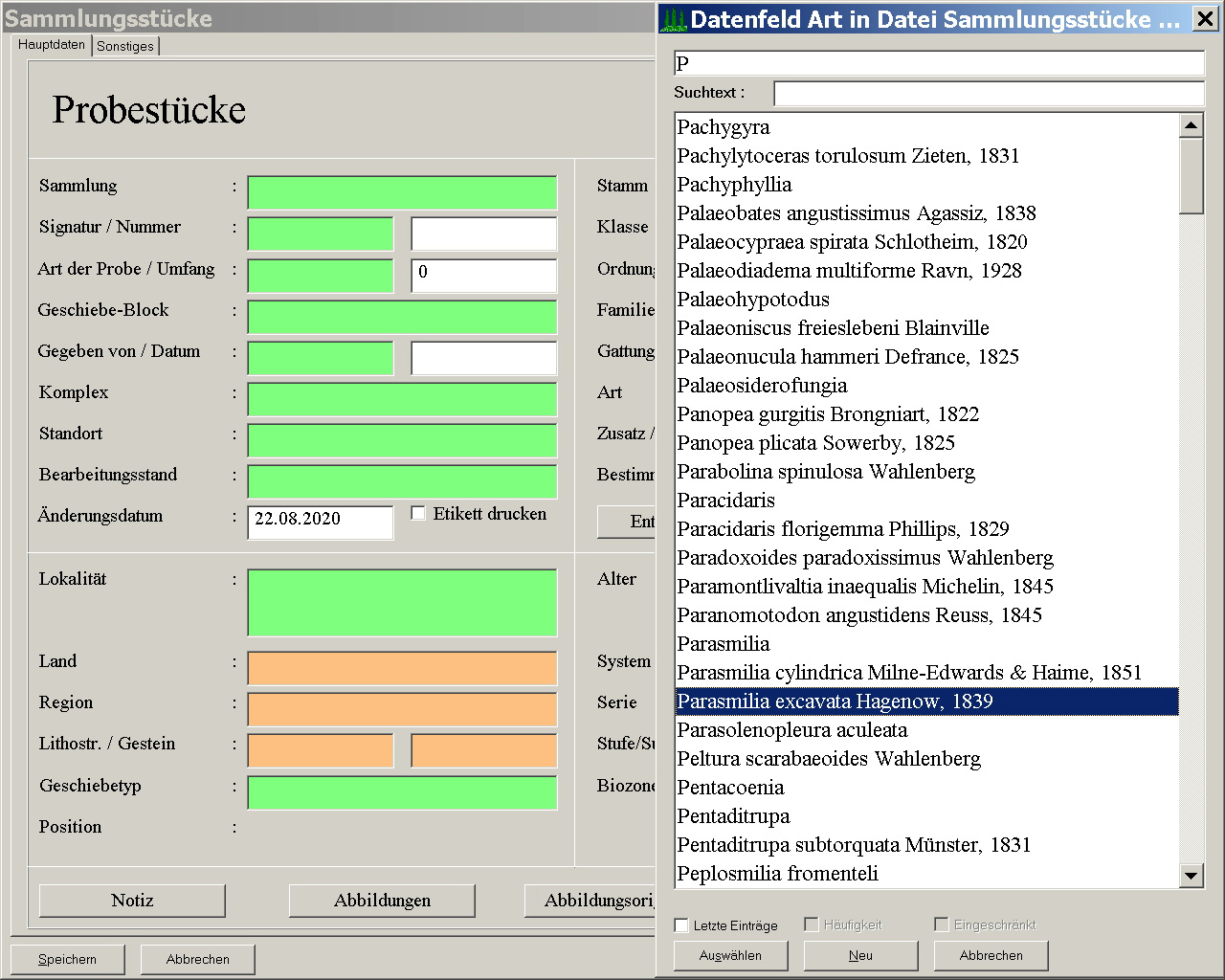
Abb. 6: Ansicht auf 1280 x 1024 Pixel vergrößern.
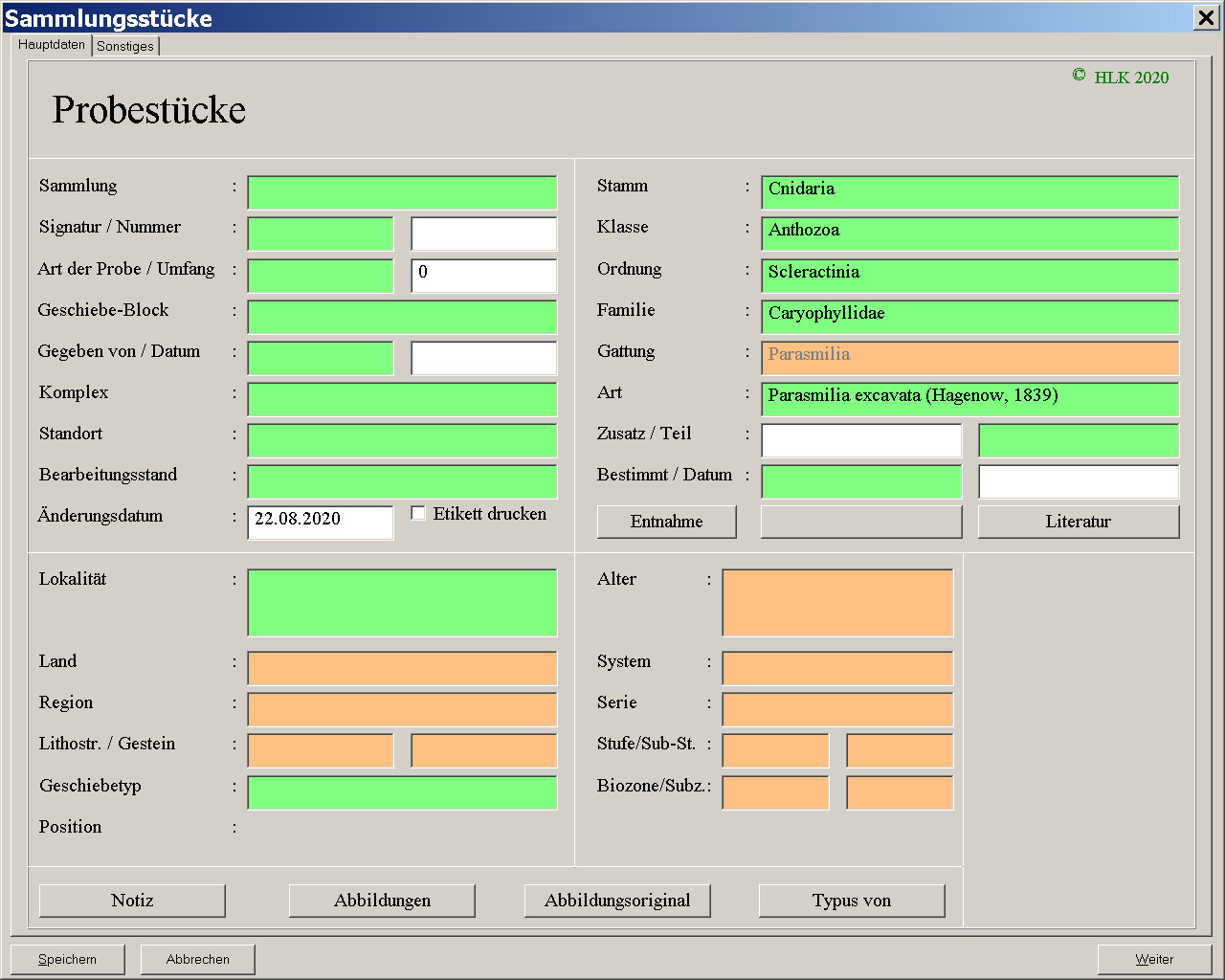
Abb. 7: Ansicht auf 1280 x 1024 Pixel vergrößern.

Abb. 8: Ansicht auf 1280 x 1024 Pixel vergrößern.
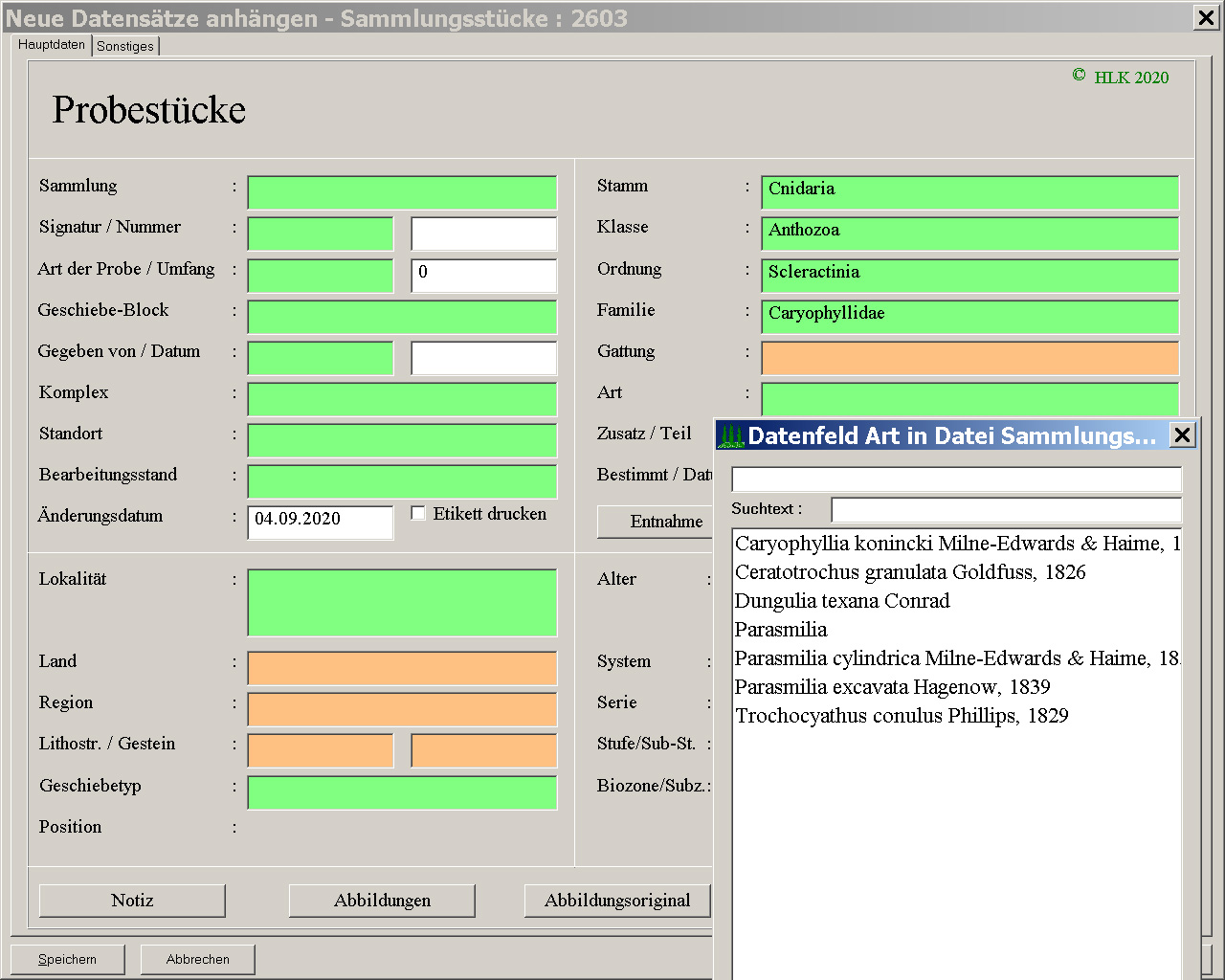
Abb. 9: Ansicht auf 1280 x 1024 Pixel vergrößern.

Abb. 10: Ansicht auf 1280 x 1024 Pixel vergrößern.
Sind nun einmal Daten erfasst, kann nicht nur nach ihnen gesucht werden, sondern man kann zum Beispiel auch sehen, von welchen Fundpunkten eine Art erfasst wurde. Diese Information findet man auf der zweiten Registerkarte in der Tabelle der Arten. Ebenso kann man prüfen, welche Arten man von einem bestimmten Fundpunkt besitzt. Diese Daten befinden sich auf der zweiten Registerkarte der jeweiligen Lokalität. Erfasste Daten können ausgegeben werden, zum Beispiel in eine Textdatei oder in die Zwischenablage. Für die Tabelle der Probestücke stehen verschiedene Etiketten zur Verfügung, die im Rich Text Format (RTF) erzeugt und im Nachhinein in einer Textverarbeitung modifiziert werden können.
Wir wollen hier nicht weiter auf Details eingehen, da diese in der Dokumentation genau beschrieben sind. Das stärkste Argument, was von Sammlern gegen Datenbanken vorgebracht wird, ist der zeitliche Aufwand. Natürlich sollte man die Zeit, die man seinem Hobby widmen kann, eher im Gelände zubringen oder beim Präparieren. Aber es stimmt nicht, dass der Aufwand für den Aufbau und die Pflege einer Datenbank hoch ist. Denn man verbringt nur ganz wenig Zeit beim Erfassen der Daten, aber – und das wird oft vernachlässigt – sehr viel mehr bei der Prüfung und Verifizierung der Daten. Die Datenbank stellt bestimmte Anforderungen an die Daten, zum Beispiel die Zugehörigkeit einer Lokalität zu einer regionalpolitischen Einheit wie dem Bundesland, die Zugehörigkeit einer Ammonitenzone zu einer Stufe und einer Serie, ebenso wie eine Gattung zu einer Familie die wiederum zu einer Ordnung gehört. Oft liegen diese Daten bei der Erfassung gar nicht vor und müssen erst recherchiert werden. Je kleiner das Arbeitsgebiet geographisch ist, umso einfacher ist auch die Verifizierung der Daten, je größer es ist, desto schwieriger. Ebenso ist ein taxonomisch eng begrenztes Gebiet einfacher zu handhaben als z. B. eine Sammlung eiszeitlicher Geschiebe, die Taxa aller Zeiten und Gruppen enthalten kann.
Download:
PalCol ist kostenlos. Es kann im Internet unter https://www.paleotax.de/pvn4d.htm heruntergeladen werden. Programm und Daten belegen nur wenige Megabytes auf der Festplatte. Besondere Anforderungen an die Hardware existieren nicht. Das Programm wurde unter Windows XP bis Windows 10 getestet. Eine Dokumentation in deutscher Sprache findet sich als PDF-Dokument auf der Seite https://www.paleotax.de/pvn10d.htm. Sowohl das Datenbankprogramm als auch die Anwendungsbibliothek werden regelmäßig aktualisiert. Das bedeutet einerseits, dass Fehler im Programm beseitigt und eventuell neue Funktionen integriert werden, andererseits werden in der Anwendungsbibliothek Veränderungen vorgenommen, zum Beispiel die Hinzufügung neuer Ausgabeformate, die Erweiterung der Datenstruktur und Erfassungsmasken oder die Verbesserung der Funktionalität. Für Verbesserungen der Funktionalität sind Vorschläge von Anwendern nicht nur willkommen, sondern sie bildeten die Basis für die gegenwärtige Version der Struktur PalCol.
Windows ist ein eingetragenes Warenzeichen.
Hannes Löser
Diskutieren Sie mit über den Artikel im Steinkern.de Forum:

